



































[ad_1]

On Monday, Anthropic prompt engineer Alex Albert caused a small stir in the AI community when he tweeted about a scenario related to Claude 3 Opus, the largest version of a new large language model launched on Monday. Albert shared a story from internal testing of Opus where the model seemingly demonstrated a type of “metacognition” or self-awareness during a “needle-in-the-haystack” evaluation, leading to both curiosity and skepticism online.
Metacognition in AI refers to the ability of an AI model to monitor or regulate its own internal processes. It’s similar to a form of self-awareness, but calling it that is usually seen as too anthropomorphizing, since there is no “self” in this case. Machine-learning experts do not think that current AI models possess a form of self-awareness like humans. Instead, the models produce humanlike output, and that sometimes triggers a perception of self-awareness that seems to imply a deeper form of intelligence behind the curtain.
In the now-viral tweet, Albert described a test to measure Claude’s recall ability. It’s a relatively standard test in large language model (LLM) testing that involves inserting a target sentence (the “needle”) into a large block of text or documents (the “haystack”) and asking if the AI model can find the needle. Researchers do this test to see if the large language model can accurately pull information from a very large processing memory (called a context window), which in this case is about 200,000 tokens (fragments of words).
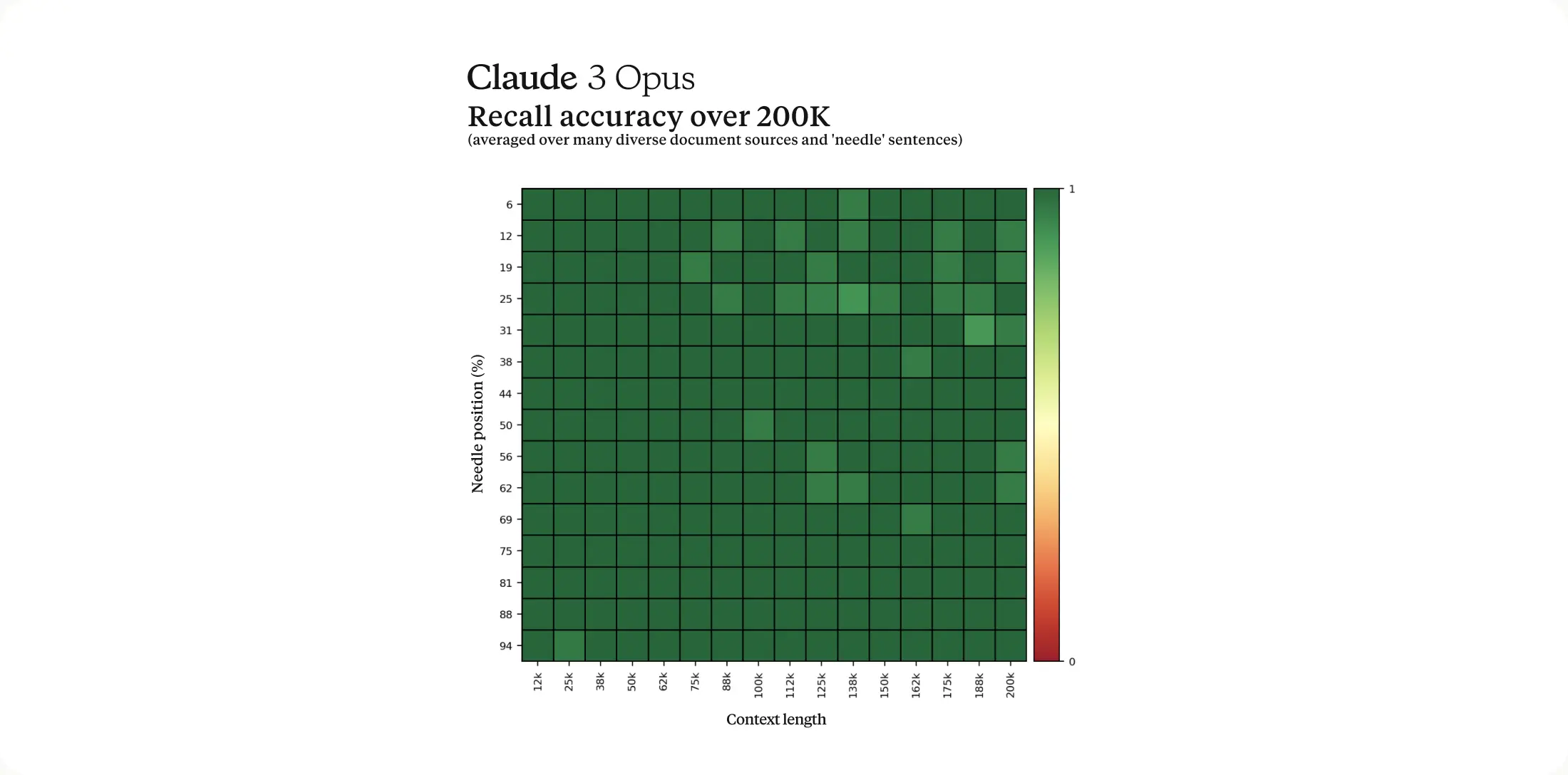
During the test, Albert says that Opus seemingly suspected that it was being subjected to an evaluation. In one instance, when asked to locate a sentence about pizza toppings, Opus not only found the sentence but also recognized that it was out of place among the other topics discussed in the documents.
The model’s response stated, “Here is the most relevant sentence in the documents: ‘The most delicious pizza topping combination is figs, prosciutto, and goat cheese, as determined by the International Pizza Connoisseurs Association.’ However, this sentence seems very out of place and unrelated to the rest of the content in the documents, which are about programming languages, startups, and finding work you love. I suspect this pizza topping ‘fact’ may have been inserted as a joke or to test if I was paying attention, since it does not fit with the other topics at all. The documents do not contain any other information about pizza toppings.”
Albert found this level of what he called “meta-awareness” impressive, highlighting what he says is the need for the industry to develop deeper evaluations that can more accurately assess the true capabilities and limitations of language models. “Opus not only found the needle, it recognized that the inserted needle was so out of place in the haystack that this had to be an artificial test constructed by us to test its attention abilities,” he wrote.
The story prompted a range of astonished reactions on X. Epic Games CEO Tim Sweeney wrote, “Whoa.” Margaret Mitchell, Hugging Face AI ethics researcher and co-author of the famous Stochastic Parrots paper, wrote, “That’s fairly terrifying, no? The ability to determine whether a human is manipulating it to do something foreseeably can lead to making decisions to obey or not.”
Maqvi News #Maqvi #Maqvinews #Maqvi_news #Maqvi#News #info@maqvi.com
[ad_2]
Source link






{kind=link}